이전 도커에 하둡설치 글에 이어서 하둡을 설정하고 실행하는 글을 작성한다.
ssh 패키지 설치 및 설정
노드 간 통신을 위해 ssh 패키지를 설치한다
yum install openssh-server openssh-clients openssh-askpass -yssh-keygen -f /etc/ssh/ssh_host_rsa_key -t rsa -N ""
ssh-keygen -f /etc/ssh/ssh_host_ecdsa_key -t ecdsa -N ""
ssh-keygen -f /etc/ssh/ssh_host_ed25519_key -t ed25519 -N ""이 때, 오타에 주의를 하자. 필자는 위 ssh 키 생성 시 오타가 나서 이 후에 진행하는 하둡 설정에서 막혔었다. 이로 인해 컨테이너를 삭제하고 다시 앞선 도커 이미지로 하둡 설치과정을 진행했다. 다시 한 번 도커의 장점을 몸소 깨닫게 되었다. 이게 만약 로컬 환경이었다면.. 오류를 바로 잡는 것만으로 많은 시간을 할애했을 것 같다.
vim ~/.bashrc스크립트를 열면, 이전에 작성한 내용들 밑에 추가로 다음 내용을 기입한다.
/usr/sbin/sshd이후 source 명령어로 스크립트를 실행
source ~/.bashrc비밀번호 없이 통신하기 위하여 공개키 및 비밀키 생성
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa생성한 공개키를 인증키로 등록한다.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysssh 연결 확인
ssh localhost
Warning이 뜨지만 무시해도 괜찮다.
Hadoop 설정
하둡 설정파일들이 있는 디렉토리로 이동한다. 이전에 환경변수로 설정한 HADOOP_CONFIG_HOME을 통해 이동
cd $HADOOP_CONFIG_HOMEvim hadoop-env.sh다음 내용을 추가한다.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.aarch64
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
데몬들이 홈으로 사용할 디렉토리 생성
이전에 하둡 홈 디렉토리로 생성한 폴더에 하위 디렉토리로 생성했다.
mkdir /hadoop_home/temp
mkdir /hadoop_home/namenode
mkdir /hadoop_home/datanode이제 하둡 설정을 위해 총 3개의 파일을 수정해야한다.
1. core-site.xml
2. hdfs-site.xml
3. mapred-sit.xml
1. core-site.xml
vim core-site.xmlconfiguratiion 안에 다음 내용을 추가한다.
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop_home/temp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<final>true</final>
</property>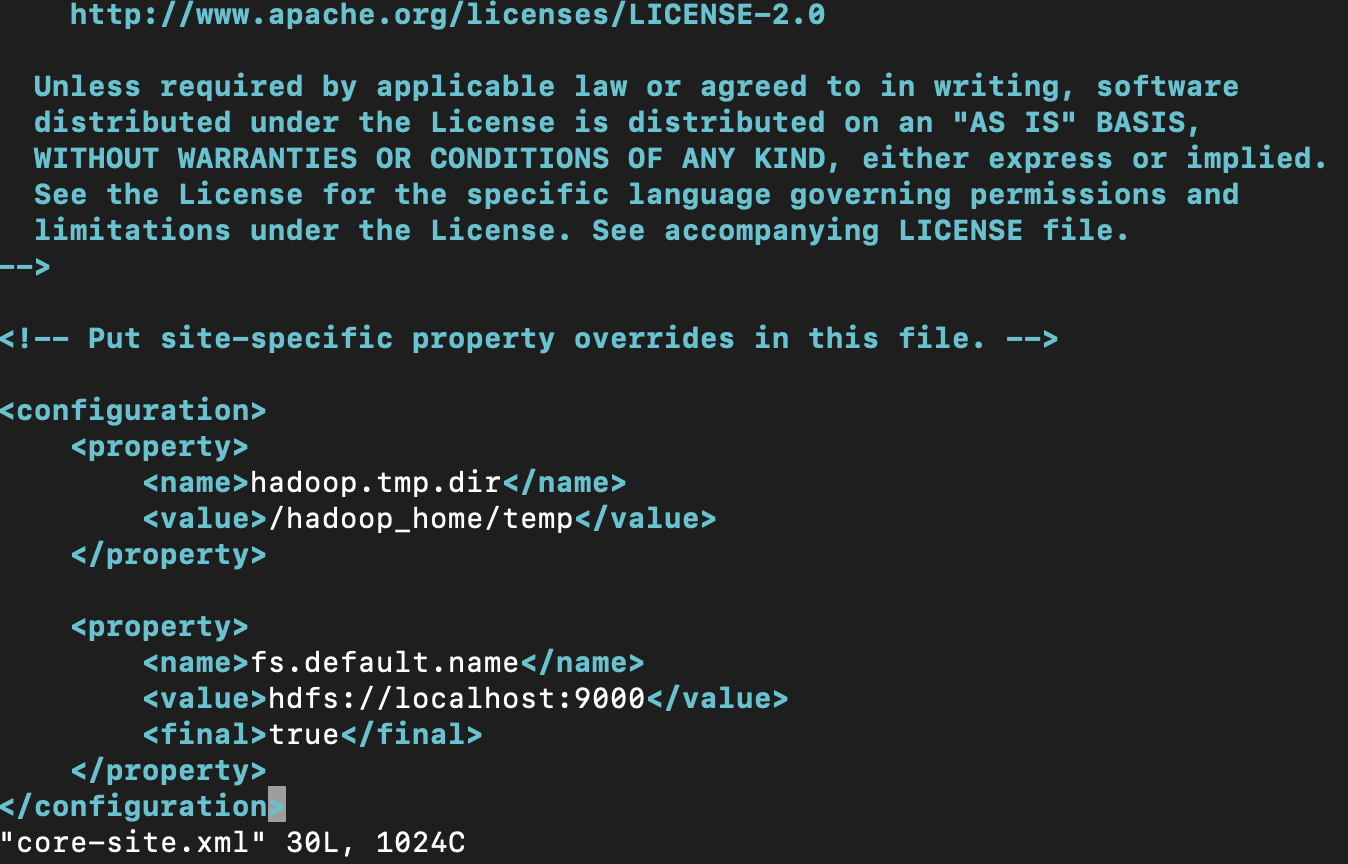
2. hdfs-site.xml
vim hdfs-site.xml마찬가지로 configuration안에 다음 내용을 추가한다.
<property>
<name>dfs.replication</name>
<value>1</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop_home/namenode_home</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop_home/datanode_home</value>
<final>true</final>
</property>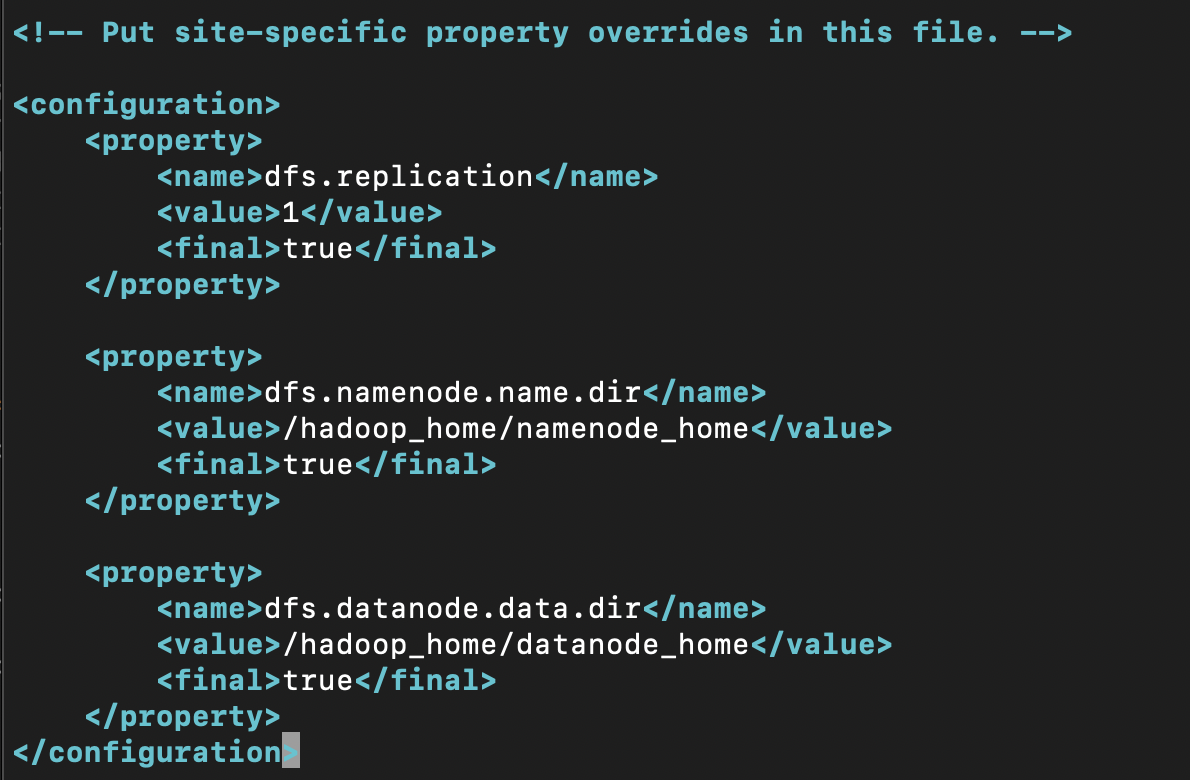
3. mapred-site.xml
vim mapred-site.xml <property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
이제 하둡 설정이 끝났으니, 하둡을 실행한다.
Hadoop 실행
namenode 포맷을 먼저 진행한다.
hadoop namenode -format새로운 터미널에서 진행상황을 커밋한다.
docker commit hadoop-base centos:hadoop
위 이미지는 commit 명령어를 실행한 후
hadoop-base2인 이유는... 이 글을 시작 때 설명한 ssh 키 설정 시 오타로 인해 컨테이너를 다시 만들었기 때문..
다시 hadoop을 설정하는 hadoop-base 컨테이너 터미널로 돌아와서, 하둡 클러스터 실행
start-all.sh다음 명령어로 실행 중인 노드를 확인
jps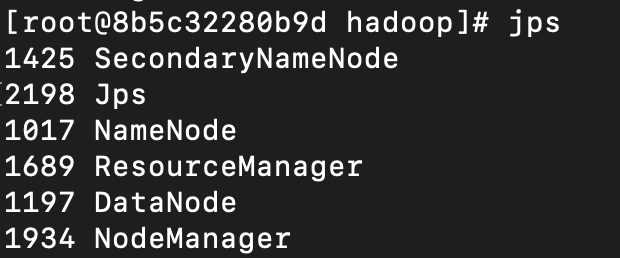
References
1. https://mungiyo.tistory.com/17?category=980499
[Hadoop] 도커(Docker)로 하둡 설치하기 (Pseudo-distributed)
이전 포스팅에서 독립실행모드로 하둡을 설치해보았다. 이번 포스팅은 하둡의 3가지 모드 중 가상분산모드로 설치해 볼 것이다. 독립실행모드가 하나의 로컬 환경으로 그냥 하둡을 설치하는
mungiyo.tistory.com
'Kubernetes' 카테고리의 다른 글
| [Docker] 컨테이너 (이미지) 백업 (0) | 2022.06.23 |
|---|---|
| Docker로 Hadoop 설치하기 (0) | 2022.06.21 |
| Docker 입문: 설치 및 실행 (0) | 2022.05.24 |